I subscribe to a lot of feeds. About 1800 I've been gathering every day since I realized aggregation sites where on the way out in the early 2010s. I've been using QuiteRSS for about a decade to skim and read these feeds. It's a solid program based on sqlite. It mostly works. Every now and then the db grows out of control and external sqlite tools have to be used to vacuum back to size. But it gets almost all feeds, displays them all properly with HTML rendering and everything looks nice. Unfortunately with 1800+ feeds it's both a bit slow to switch between feed directories (after they're ~10k-100k feed entries in each) and I don't want to prune more often using it's tools because it's *slow* and tedious. It also uses a *lot* of ram, 1500MB rss.
Since we live in a world where we can just describe applications and debug them into existence I decided to try making my own feed reader. One that would be slim on RAM and performant even with tens of thousands of entries. I'd do this by only ever dealing with text. No HTML rendering. Just the best text interpretation possible. I don't know if I've succeeded. It certainly uses very little RAM. It's ~100MB rss. So far I only have ~thousands of entries in each directory but it is so snappy as to not be noticible. Text render is acceptable, there's some utf8 issues, some encoding issues, but everything is very readable.
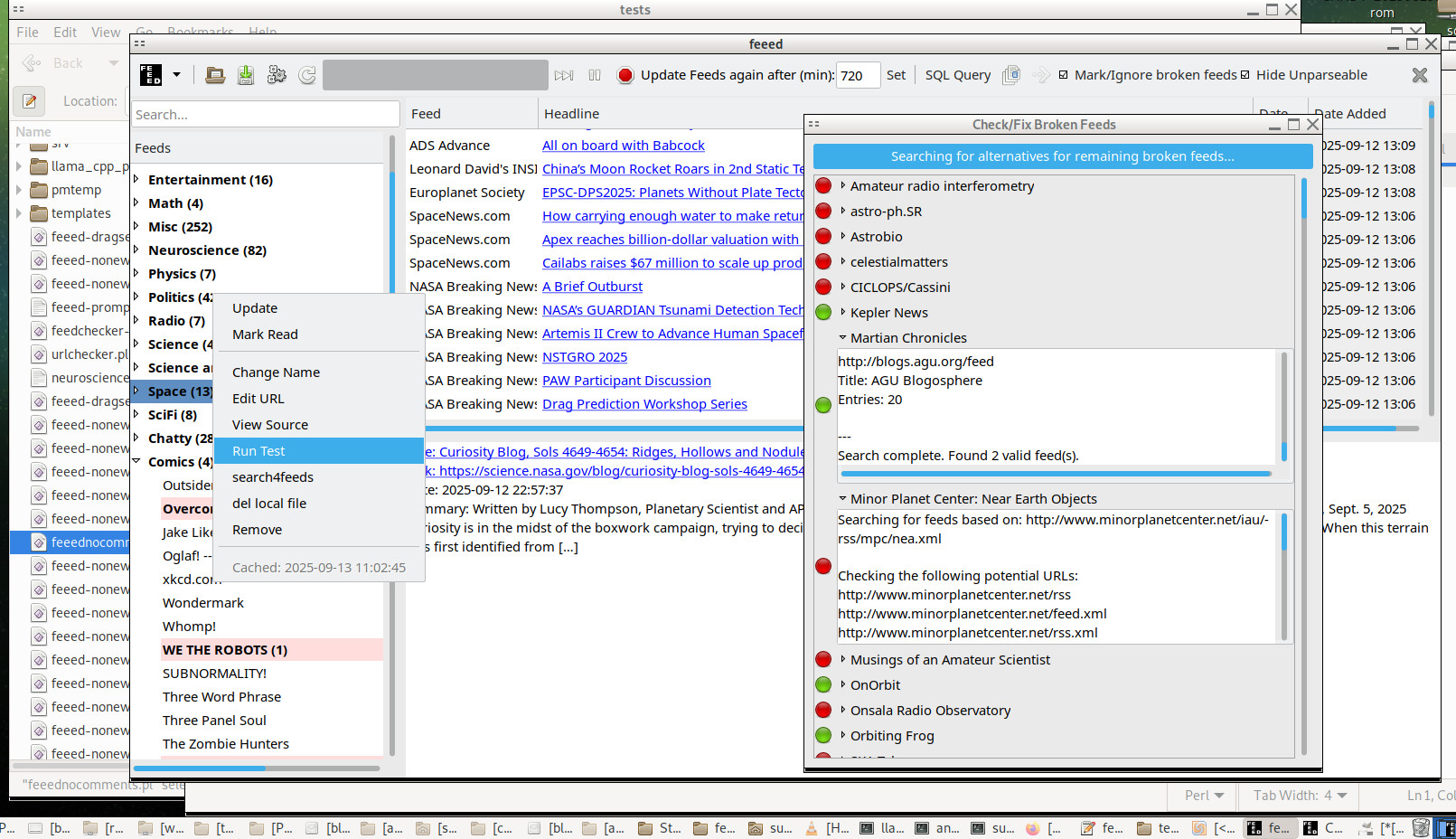
Where feeed.pl really shines is in loading your .opml feed list and then figuring out which ones are broken and providing the tools to quickly fix it. The right-click context menu 'run test' provides detailed http header, request, and reply information as well as multiple alternative feed parsing regexs to figure out why a feed might not parse despite replying to an HTTP request. For truly broken feeds (bad domain, 503, permanently moved, etc) that are automatically detected and marked the right-click context menu 'search4feeds' uses a list of common feed names and mixes up site domain, dir, and subdomains to try to find common feed URL patterns for feeds that might have moved due to a change in content management system or the like. feeed.pl also keeps a copy of all http responses on disk in raw form for debugging which can be viewed with 'view source' right clicking on a feed.
And File->Check/Fix Broken... does what is shown in this screenshot. It exclusively tries all marked broken feeds once more, then attempts to guess feeds URLs and changes the light to green if there is one. Feedburner gives lots of false positives.
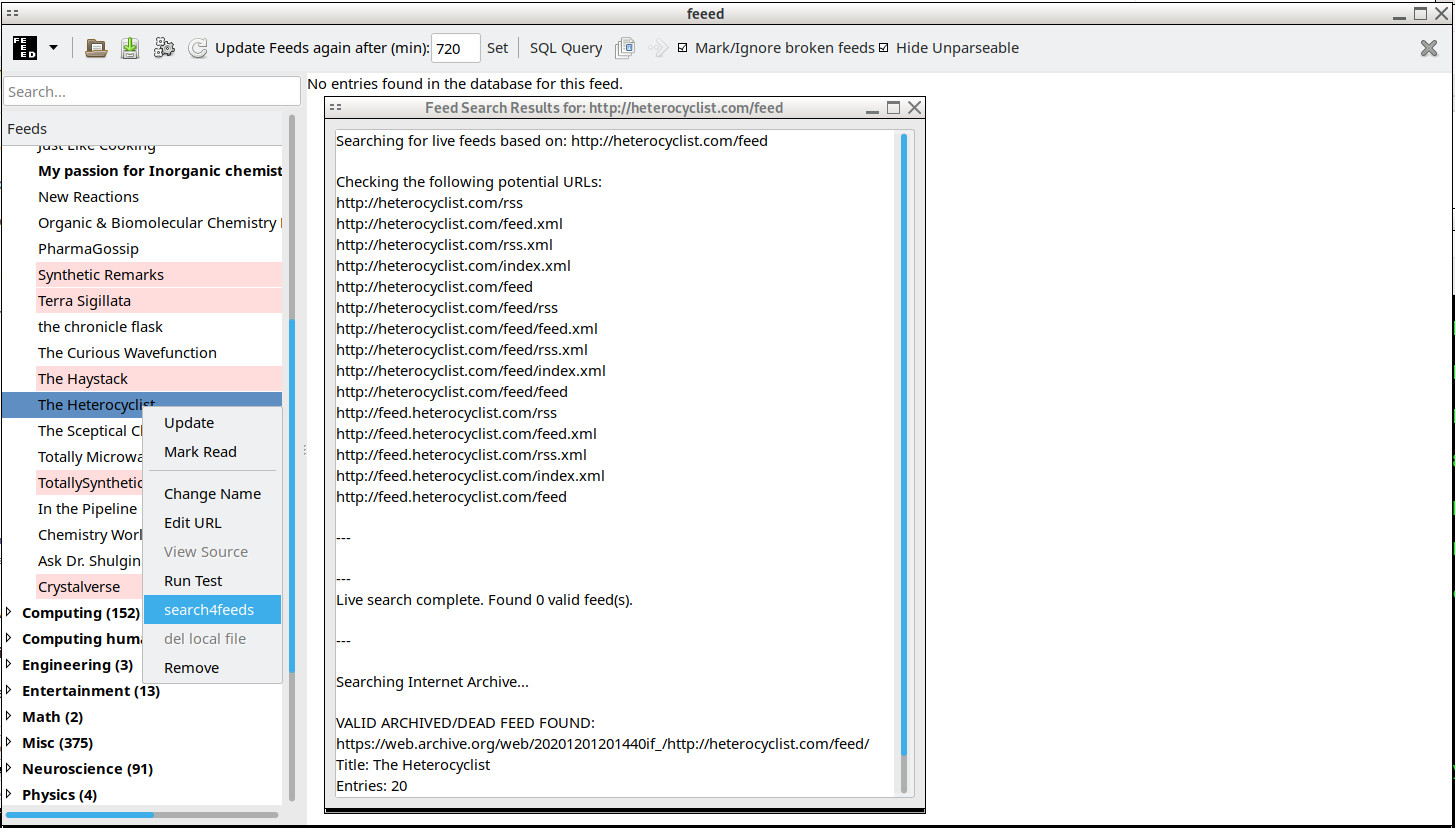
It's a lot easier to find and fix broken feeds in feeed.pl than it is in QuiteRSS. And for quick skimming of news that doesn't need all the HTML rendered glory and utility it does as a main feed reader.
But since I made this to scratch my own itch I didn't really bother with max ease of install. I use a lot of not normally installed by default perl libraries like AnyEvent, AnyEvent::HTTP, XML::LibXML, and use XML::Feed (which are backed up by many layers of regex fallbacks) and SQLite via DBI. So for a Debian alike, 'libanyevent-perl libanyevent-http-perl libasync-interrupt-perl libguard-perl libdbi-perl libdbd-sqlite3-perl'. Among others I probably missed because my machines all have so many perl libs installed manually.
I doubt anyone wants it, but, here's feeed.pl (136KB)
It creates a new directory in ~/.config/ by default called ~/.config/feeed/. Within ./feeed/ are the feeds.sqlite feed data db, ./feed/.feeedconfig which is a Storable hash dump of the feeed.pl configuration options, and the directory ./feeed/feeds/ which contains all the folders you create or imported from the .opml and within those subfolders are the raw HTTP responses from the feed URLs. Also temporarily in ./feeed/ during program execution are the temp files feeds.sqlite-wal and feeds.sqlite-shm.